
Social Information Network Analysis and Engineering
有趣的内容
Introduction
Key takeaways:
- Network defines the interactions between the components
- How do we reason about networks?
- Empirical: Study network data to find organizational principles
- Mathematical models: Probabilistic, graph theory
- Algorithms for analyzing graphs
- 我们study network是为了achieve什么?
- Paterns and statistical properites of network data
- Design principles and models
- Understand why networks are organized the way they are (Predict behavior of networked systems)
- 我们要学习network的什么?
- Structure & Evolution
- Processes (Networks provide ‘skeleton’ for spreading of information) & Dynamics (information是怎么传播的)
Social Media
Graph & Sociology
这部分定义的def包括strong / weak ties, bridge等,都在下面出现过,故此处略。
那么,通过观察图像以及bridge的def我们可以发现,communities之间都有weak ties (bridges),那么可以说明实际上,bridge是一种将communities联系起来,构成一个society的key item
而且也跟bridge处在communities中间这个位置有关,下文也有简述,就是bridge must necessarily carry any new information,直观的体现就是下文的job finding
Theorems
“The Small World Problem”: 若在US随机sample两个人,他们认识的概率有多大?
Neocortex (新皮层): 这个brain的一个组织,根据调查,neocortex的大小和当前primate(灵长类动物)的group大小有紧密关系
根据这个可以得出一些推论:
- Each individual只能maintain一定数量的relationship,因为bounded by neocortex size
Network
Key Takeaways:
Bridge Edge: 割边; Articulation Point: 割点
Largest Component我们也管它叫Giant Component。管那些游离,无degree的点叫做Isolated node
Weakly connected directed graph: 和强连通图不同,他不是strongly connected,但是假如把所有的direction去掉变成undirected graph,他应该要是连通的
DAG全称Directed Acyclic Graph
Adjacency Matrix 邻接矩阵。注意,邻接矩阵里面存的是weight,而不是是否连通 (0 / 1)。只能说在unweighted graph里面 $A$ 的元素值都是 0 / 1
Node degree:
- Average degree: $\bar{k} = \left<k\right> = \frac1{N}\sum\limits_{i = 1}^N k_i = \frac{2E}{N}$
- $\overline{k^{in}} = \overline{k^{out}}$
Bipartite Graph: 二分图
Degree Distribution $P(k)$: Probability that a randomly chosen node has degree $k$
$P(k) = \frac{N_k}{N}$,其中 $N_k$ 是度数为 $k$ 的node的个数

如果两个node没有连接,那么他们之间的距离通常被认为是infinite
Diameter: 图的直径
Average Path Length: $\bar h = \frac1{2E_{max}} \sum\limits_{i, j \neq i} h_{ij}$ where $h_{ij}$ is the distance(shortest-path, geodesic) from node $i$ to node $j$
这里 $E_{max}$ 指的是maximum number of edges in an undirected complete graph,即 $E_{max} = \frac{N(N - 1)}{2}$
$\bar h$ 下面要除以2是因为我们会把pair $(i, j)$ and $(j, i)$都算一遍
$h_u (v)$ 指的是以 $u$ 为源点,到 $v$ 的距离
Clustering Coefficient 是用来衡量群聚程度的measure,值越高越群聚
Computation:
$$
C_i = \frac{2e_i}{k_i (k_i - 1)}
$$
其中,$e_i$ is the number of edges between the neighbors of node $i$Average CC: $C = \frac1N \sum\limits_i^N C_i$
Web as a grph (此处应该是指的网页操作逻辑,以及通过链接的互相访问)
Nodes = Web pages
Edges = Hyperlinks
上面是web的真实结构,其中T、endrils指那些能从IN和OUT到达,但是不能反过来的web pages;Tubes指能从IN到达,最终能到达OUT的web pages
Small World
Random Graph Model
Erdös-Renyi Random Graphs: $G_{n, p}$ is a undirected graph with $n$ nodes, and all edges apprear i.i.d. with probability $p$
根据上面的def,我们也可以得到 $G_{n, p}$ generates exactly $E$ edges的概率
$$
P(E) = { E_{max} \choose E } p^E (1 - p)^{E_{max} - E}
$$
那么说完了edge数,关于每个点的期望degree又如何?
Let $X_v$ be a random variable measuring the degree of node $v$, and $X_{v, u}$ be a $\{0, 1\}$-random variable which tells if edge $(v, u)$ exists or not。显然,$X_v = X_{v, 1} + X_{v, 2} + \cdots X_{v, n - 1}$
$$
E[X_v] = \sum\limits_{j = 0}^{n - 1} jP (X_v = j) = \sum_u E[X_{v, u}] = (n - 1)p
$$
因为 $v$ 向每个 $u$ 有edge的概率是 $p$
现在来考虑graph整体的degree distribution。让 $P (k)$ be the fraction of nodes with degree $k$
$$
P(k) = { n - 1 \choose k } p^k (1 - p)^{n - 1 - k}
$$
我们可以发现,degree distribution实际上是bionomial的,并且上面计算 $P(k)$ 的逻辑也是和计算单独node的expected degree是一样的。
因为他的分布是bionomial的,所以也很容易可以得到degree distribution的mean和variance
$$
\bar k = (n - 1)p \
s^2 = (n - 1)p(1 - p)
$$
而且对于random graph,要计算他的clustering coefficient
$$
E[e_i] = p \frac{k_i(k_i - 1)}{2}
$$
这个是因为对于点 $i$,他一共有 $\frac{k_i(k_i - 1)}{2}$ 个neighbor点对,每个点对有 $p$ 的概率连接,那么其CC值则为
$$
C = \frac{pk_i (k_i - 1)}{k_i(k_i - 1)} = p
$$
可以看得出在random graph中,node的CC都是很小的,说明群聚程度不高
而且根据 $\bar k$,即mean degree distribution,我们还可以大致确定这个random graph的components大小
- $(n - 1)p < 1 \Rightarrow \text{components are small}$
- $(n - 1)p > 1 \Rightarrow \text{a giant component emerges}$
上面这个叫做 phase transition
Small World Evolution (Watts & Strogatz)
事实上,real world social networks are
- High clustering
- Small dismeter (“Small World”)
那么,我们要怎样才能构造出这样的graph呢?
先start from a low-dimentional regular lattice
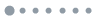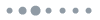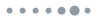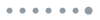
这张图中,each node is connected to its $\alpha$ nearest neightbors,从结果上来看,它是
- High clustering
- High diameter $O (n)$,以及average distance也是 $O (n)$
但是如果我们有一张随机图,
它是
- Small clustering
- Small diameter $O (\log n)$。注意,random graph的diameter和average distance都是log级别的
那么我们要怎么样将我们的regular lattice向这个random graph转换?我们需要rewire
- 每次对一个node,遍历他开始的每条edge,我们有 $p$ 的概率将其rewire到一个uniformly chosen node at random over the entire ring
在对每个node都做完后,这个rewire就完成了,那么显然,里面有 $p$ fraction of nodes被rewire了
如上图,就visualize了这个过程
若我们将过程中的CC和diameter图表化,可以得到
从上图我们可以发现,clustering coefficient在 $p$ 小的那段区间里变化很小,但是对于mean distance来说变化就十分巨大,所以说
It takes a lot of randomness to ruin the clustering, but a very small amount (of long-range edges) to create shortcuts.
那么从上图我们就可以发现,比如在 $p \in [0.01, 0.1]$ 的区间中任选一个 $p$,就可以得到high clustering coefficient but small diameter的图了
上述过程是由Watts-Strogatz提出的
但是值得注意的是,这个model does not lead to the correct degree distribution,因为most nodes have similar degrees due to the underlying lattice
Community
Friendship可以被分为两种情况来进行讨论
- Structual,这部分讨论的实际上就是人际网,即graph structure
- Interpersonal,这部分讨论的是人与人之间的羁绊,人和人有亲疏之分,所以分为weak or strong ties。weak指疏,strong则指亲
我们一般称graph里的connection为structural的,而interpersonal,或是说是现实意义的关系connection为social connection。所以一般weak和strong都描述的是social connection。
Granovetter也给structural和social的connection建立了联系,这个联系包含两部分:
Embeddedness of an edge: number of common neighbors the two endpoints have
Edges spanning different parts of the network are socially weak。这句话的structural理解是,比如这个edge可以是两个连通块中间的bridge,那么就会给人一种摇摇欲坠之感,因为感性理解一下,一般连通块内的connection是比较strong的。那么socially speaking,这个bridge相当于表示两撮人中间正好有两个人认识,但是一般来讲他们不会那么熟悉,所以可以generally认为是weak的。
The long range edges allow you to gather information from different parts of the network and get a job. Structurally embedded edges are heavily redundant in terms of information access
这两句话主要是在阐述,在获得新information方面,比如job information,weak ties会比strong ties更有用。虽然你的close friends更乐意于为你提供信息,但是因为the environment you exposed十分类似,所以经常并不能为你提供什么有效信息;反之,acquaintance,即你的weak ties,因为和你的环境差很多,倒是经常能为你提供你们圈子所不知道的信息,所以在information access方面是更有效的。
Triadic Closure
从一个简单的模型开始看起,Triadic Closure
Theorem: If two people in a network have a friend in common, there is an increase likelihood they will become firends themselves
Example: B - A - C. Then B is more likely to meet C
Explanation from social perspective
- B and C trust each other since they have a friend A in common
- A has an incentive to bring B and C together
Explanation from structural perspective (Granovetter’s Explanation)
这种情况下,clustering coefficient一般都比较大
首先给出几个定义:
Bridge edge就是割边,local bridge就是不是bridge,但是endpoints没有公共friend的边,所以他们的span会大于2。
Strong triadic closure就是B - A - C的案例中,如果B - A和A - C都是strong tie,那么B、C之前应该也要有一条边,即他们应该会认识。
那么对于最后一条Fact,也可以prove by contradiction,首先a在一个strong triadic closure里面,也就是说他至少有两个strong ties,假如上图a - b是strong tie,那么很明显,根据triadic closure,a的某个friend和b之间应该是要认识的,至少有一条edge;然而根据local bridge的定义,a & b have no friends in common,所以命题为假。
Neighborhood Overlap
$$
O_{i, j} = \frac{N (i) \cap N (j)}{N (i) \cup N (j)}
$$
where $O_{i, j}$ 是用来measure overlap的值,$N (i)$ 表示node $i$ 的neighbor集合,所以这个公式实际上就是$i, j$公共neighbor和所有neighbor的个数比
从上图我们可以看出,当 $O_{i, j} = 0$,则说明 $(i, j)$ 是local bridge
Relationship
当我们通过cell-phone network画图比对,可以发现一个现象
Edge strenghth increases with neighborhood overlap
而在观察图的时候,我们还可以发现一个现象
Weak ties serve to link different tightly-knit communities that each contain a large number of stronger ties
那么要怎么验证这个结论呢?一种方法是比较用strength或者overlap值给node排序,然后按照low-to-high和high-to-low的顺序移除node,看看graph中最大连通块的size会怎么变化 (即看连通性怎么变化)。
结论是我们会发现这size确实在low-to-high的顺序中下降的更快,说明我们破坏weak ties更容易破坏graph的整体结构与连通性,特别是当用overlap值排序的情况下。所以可以发现weak ties在maintain graph structure这块起了很大的作用。
那么我们现在可以得到一个conceptual picture of networks:
Weak ties are crucial for maintaining the network’s structural integrity, but strong ties are for maintaining local communities
Passive Engagement
但是你会发现,我们虽然称那些close friends为strong ties,但真正有持续交流的又有多少?事实证明,没有多少,因为对于一个strong tie,你就要invest很多time & efforts to maintain the relationship。所以调查发现,一直维持联系的,特别是mutual的联系的friend特别少,虽然他们名义上是strong tie。
所以就有了这个词语: Passive Engagement
Passive engageme: keep up with friends by reading about them even in the absence of communication
How to find communities?
上面关于communities的一些基础概念都聊完了,那么现在聊一些更practical的东西,就是我们要怎么找到这些communities呢?
首先给出一个关于Edge Betweenness的定义,它表示number of shortest paths passing over the edge。
而且注意,edge betweenness的定义还有一条: If there is more than one shortest path between a pair of nodes, each path is assigned equal weight such that the total weight of all of the paths is equal to unity.
Compute Edge Betweenness
此处只展示从某个源点 $s$ 开始的计算,要得到最终答案再把其他点全部过一遍就好了。该过程分为两部分,上图展示了整个计算流程
Part I,计算 $s$ 到每个点的最短路径数,用 $w_i$ 指的是从 $s$ 到点 $i$ 的最短路径数
就是个普通BFS的过程。
Part II,计算每个edge的betweenness,这部分需要着重注意,这是个从下往上倒推的过程
Find every ‘‘leaf’’ vertex $t$, i.e., a vertex such that no paths from $s$ to other vertices go though $t$. 比如在上图中,leaf就是最底下的 $F, G$
For each vertex $i$ neighboring $t$, assign a score to the edge from $t$ to $i$ of $\frac{w_i}{w_t}$
比如在上图中,就是 $(D, F) = \frac23, (E, F) = \frac13, (E, G) = \frac11 = 1$
Now, starting with the edges that are farthest from the source vertex $s$ — lower down in a diagram such as Fig. 4(b)—work up towards $s$. To the edge from vertex $i$ to vertex $j$, with $j$ being farther from $s$ than $i$, assign a score that is $1$ plus the sum of the scores on the neighboring edges immediately below it (i.e., those with which it shares a common vertex), all multiplied by $\frac{w_i}{w_j}$
我的理解实际上就是你每次找离 $s$ 最远的边进行更新,比如像上图还未更新的最远的边就是 $BD, CD, CE$。假设一条边是 $(i, j)$,并且 $j$ 到 $s$ 的距离比 $i$ 更远,即 $j$ 更“深”,那么最终 $(i, j)$ 的edge betweenness就是1 + 素描of $j$下面的边的edge betweenness,最终再乘上一个 $\frac{w_i}{w_j}$
Repeat from step (iii) until vertex $s$ is reached.
Girvan-Newman
那么现在就有一个GN算法可以解决finding communities的问题了,他的流程很简单:
- 首先我们的network是undirected & unweighted的
- Calculate betweenness of edges
- Remove the edge with the highest betweenness (如果有两条最大betweenness的边,全部remove)
- 重复上述操作知道no edges left
在每一步拆解的过程中,那些connected components就是communities
这本质上是在做network的hierarchical decomposition
Modularity
但是我们会发现,我们根本不知道要把communities拆成多少个,所以必须要有一个度量的方法,那么现在就有一个measure指标,叫做Modularity $Q$
Modularity $Q$: A measure of how well a network is partitioned into communities
一个community如果划分的好那么他们的内部similarity是比较高的,而外部则要比较低
同时我们还需要一个参照物来判断我们当前的划分到底如何,那么就可以使用random graph,用这个random的期望来作参照,我们他叫做Null Model
Null Model: Same degree distribution but random conections
假设 $m$ 是network的总edge数,the expected number of edge between nodes $i$ and $j$ of degree $k_i$ and $k_j$ equals to $\frac{k_ik_j}{2m}$
同时假设我们的original graph是 $G$,拥有邻接矩阵 $A$,分割完后当前community集合是 $S$,要计算Modularity,Mathematically
$$
\begin{aligned}
Q (G, S) &= \frac{1}{2m} \sum_{i, j} \left(A_{ij} - \frac{k_ik_j}{2m}\right)[\text{$i$, $j$ belong to the same community}] \
&= \frac1{2m} \sum_{s \in S}\sum_{i \in s}\sum_{j \in s} \left(A_{ij} - \frac{k_ik_j}{2m}\right)
\end{aligned}
$$
如果 $Q = 0$,就说明我们当前的划分和random graph没区别,说明分的比较差,$Q$ 值要越高越好
And it is positive if the number of edges within groups exceeds the expected number
最后给出一张division & modularity的同步图
Centrality
Centrality指的是一种measure中心的办法,方法有很多,比如计算Betweenness Centrality
Normalization
实际上就是每个点的degree除以$N - 1$
Normalization的意义:
- 可以让我们compare graphs with different sizes
Betweenness Centrality
计算方法是计算每个点被几条shortest path经过。Concretely,
- Find all pairs of nodes
- Determine shortest paths
- Count shortest paths through a node
Mathematically
$$
C_B (i) = \sum_{j \neq k} g_{j, k} (i)
$$
where $g_{j, k} (i)$ refers to the number of shortest paths connecting $j$ and $k$ passing through $i$
$$
C_B (i) \in [0, \frac{(n - 1)(n - 2)}{2}]
$$
根据Betweenness centrality计算得到结果较大的node的意义是,they are individuals controlling the flow around a network。并且也是individuals whose removal from the network will disrupt interactions the most。
我们可以也将其normalized:
$$
C’_B (i) = \frac{C_B (i)}{\frac{(n - 1)(n - 2)}{2}}
$$
Closeness Centrality
这个centrality关注的不是一个点多么“中间”,没有那么多interactive friends,而是central if it can quickly interact with all others, which measures the ‘average’ distance to the other nodes in the netwrok.
Closeness centrality = ‘average’ distance = 1 / farness = 1 / sum geodesic distance = 1 / sum length shortest path
Mathematically
$$
C_c (i) = \frac{1}{\sum\limits_{j = 1}^N d (i, j)}
$$
where $d (i, j)$ refers to the shortest path distance between $i$ and $j$
Range of closeness centrality:
$$
C_c (i) \in [0, \frac1{N - 1}]
$$
Normalization:
$$
C’c (i) = \left[\frac{\sum\limits{j = 1}^N d (i, j)}{N - 1}\right]^{- 1}
$$
如果normalization后某个$i$的$C’_c (i) = 1$,则说明他connect to all other nodes
Table
Eigenvector Centrality
Eigenvector centrality的衡量标准是,你和important的人的connection越多,你自己越important。
Freeman’s Network Centrality (Overall Centrality of the Graph)
Formula
$$
C = \frac{\sum\limits_{i = 1}^g [C (n^) - C (i)]}{\max \sum\limits_{i = 1}^g [C (n^) - C (i)]}
$$
这里的 $C$ 可以是任何centrality的measurement,比如可以是$C_D$ (degree centrality),$C_B$之类的。
$C (n^*)$ refers to largest value of $C (n)$ for any node in the network.
$g$ 是graph的node个数,分母是any graph with $g$ nodes可以整出的最大$C (n^*) - C (i)$的sigma值,比如对于degree centrality分母值为$(N - 1)(N - 2)$,即菊花图
$$
C \in [0, 1]
$$
$C = 0$ when al nodes have exactly the same centrality index
$C = 1$ if one node completely dominates the other nodes
Prestige of a node
相较于Centrality focuses on both入度和出度,Prestige只focus入度,即当前节点作为recipient的情况,generally,一个点的入度越多,它越prestigious
Degree Prestige
Formula
$$
P_D (i) = \frac{d_I (i)}{n - 1}
$$
这里 $d_I (i)$ 指的是 $i$ 的入度
Closeness Pretige
$$
P_C (i) = \frac{|I_i|}{\sum_{j \in I_i} d (i, j)}
$$
此处 $I_i$ refers to nodes that can reach $i$,$d (i, j)$ refers to the length of shortest path between $i$ and $j$
For example,
Betweenness Prestige
$$
C_B (i) = \sum\limits_{j \neq k}\frac{g_{j, k} (i)}{g_{j, k}}
$$
这里和betweenness centrality不同的是,$g_{j, k}$ 指的是所有paths between $j$ and $k$,而不是仅包括shortest path了。
同时要注意的是,若要对其做normalization,要除以的是$(n - 1)(n - 2)$而不是$\frac{(n - 1)(n - 2)}{2}$
Directed Geodesics
Geodesics实际上指的就是shortest path。
PowerLaw
Surprisingly, real world networks的degree distribution实际上是power law的而不是类似于bell-shaped那种近似normal distribution的,即power law distribution。这个distribution在log-log plot里面是一条直线。
这其中大部分的点都是small degree的,但是也存在degree非常大的点。
那么他和exponential distribution又有什么差别呢?实际上从图表中来看可以发现,对于power-law,$\log (p_k) \sim -\alpha k$,即他在log-log plot中log (x)和log (y)成正比;而对于exponential,则变成了$p_k \sim e^{-ak}$。其中,$p_k = \frac{|\{u | d_u = k\}|}{N}$。要究其区别,就是exponential是$e^{-x}$,而power-law是$x^{-\alpha}$
从结论上来讲,power-law distribution的PMF是
$$
p (k) = Pr (deg (v) = k) = Z \cdot k^{- \alpha}
$$
我们称这个 $Z$ 为normalizing constant,而这个 $\alpha$ 一般来说是满足 $2 < \alpha < 3$
其PDF为,
$$
Pr (X \le k) = \int_{x_{min}}^{\infin} p(x) \text{d}x = 1 \Rightarrow Z = (\alpha - 1)x_{min}^{\alpha - 1}
$$
Therefore,
$$
p(x) = \frac{\alpha - 1}{x_{m}} \left(\frac{x}{x_{m}}\right)^{- \alpha}
$$
其中 $x_m$ 就是 $x_{min}$。同理也可以得到,
$$
E[x] = \frac{\alpha - 1}{\alpha - 2}x_{m}
$$
从结果可以发现,对于 $\alpha \le 2$,$E[x] = \infin$;对于$\alpha \le 3$,$Var[x] = \infin$,那么显然对于real network,$E[x] = \text{constant}$ & $Var[x] = \infin$
我们管这种满足power-law的network叫做Scale-free (power-law) network
那么怎么去estimate $\alpha$呢?
- Plot a CCDF (Complementary CDF) $P (X \ge x)$
- Compute $\alpha’$ —— the slope of $P (X > x)$,注意,这个 $\alpha’$ 是正数,即signed slope的绝对值
- Estimate $\alpha = 1 + \alpha’$
为什么能这么计算呢,因为实际上 $P (X \ge x) \varpropto x^{- (\alpha - 1)}$
我们称一个distribution是heavily tailed if:
$$
\lim\limits_{x \rightarrow \infin} \frac{P (X > x)}{e^{- \lambda x}} = \infin
$$
Model: Preferential Attachment
现在的问题是,我们能不能找到一个model, which can generate a power-law distribution network
那么preferential attachment model就是其中一个能满足这个性质的model,他的构造过程是这样的:
其中 $\sum_j k_j$ 指的是所有node的degree总和
这个model是在陈述一个fact,New nodes are more likely to link to nodes that already have high degrees,即rich get richer
Model: Copying Model
另一种model叫做copying model,他的流程如下:
后面的copy the i-th link of the prototype node应当指的是edge的另一端和i-th link一样(不确定,保有疑问)
该模型可以generate出来的network满足
$$
P (d_i = k) \varpropto k^{- (1 + \frac1{1 - p})}
$$
从此可以得到 $\alpha = 1 + \frac1{1 - p}$
Cascading
When people are connected in networks to each other then they can influence each other’s behavior and decisions. This is called Cascading Behavior in Networks.
这种diffusion的现象可以构造出几个model
Probabilistic models:
Models of influence or disease spreading —— An infected node tries to “push” the contagion to an uninfected node
Decision based models:
A node observes decisions of its neighbors and makes its own decision
为什么我们要discuss diffusion现象?拿现实生活中的事件为例,我们就是在探讨tendency when people engage in activities such as: forwarding message, joining groups…
接下来重点讲解decision based models
首先,要make decision是,我们需要两个最基本的前提ingredients
- 一个是Payoffs, i.e., utility of making a particular choice,即做出这个选择得到的效用
- 另一个是Signals,他包括两块
- Public information: What your network neighbors have done
- Private information: Something you know or Your belief
Game Theoretic Model of Cascades
这是一个最简单的情况,每个node只有两个behavior的选择,A & B
You gain more payoff if your friend has adopted the same behavior as you. Concretely,
那么对于一个node $v$ 的payoff我们可以这样计算:
假设 $v$ 有 $d$ 个neighbor,然后其中 $p$ fraction选择了behavior A,剩下B,那么
$$
\text{Payoff}_v =
\left\{
\begin{aligned}
& apd ~ \text{if $v$ choose A} \ \text{if $v$ choose B}
& b(1 - p)d ~
\end{aligned}
\right.
$$
所以 $v$ choose A if $apd > b(1 - p)d \Rightarrow p > \frac{b}{a + b}$
Contagion
这边探讨的是probability model
我们拿virus传播为例,假设每个病毒点传播virus的概率是 $\beta$,自己heal的概率是 $\delta$
SIR Model
在该模型中,每个点有三个阶段:
Susceptible: 如果一个点的neighbor染上了virus,那么他是一个潜在感染点
$S$ 指number of susceptible individuals
Infected: 指被感染的点
$I$ 指number of infected individuals
Recoverd: 指被感染,但heal了的点
$R$ 指number of recovered individuals
Total population $N = S + I + R$
这是固定当前是某个时间点,那么number of individuals who become infected per unit of time = $\beta SI = pcSI$
Therefore,
$$
\frac{\mathcal{d} S}{\mathcal{d} t} = - \beta SI, \frac{\mathcal{d}I}{\mathcal{d}t} = \beta SI - \delta I, \frac{\mathcal{d} R}{\mathcal{d} t} = \delta I
$$
其中 $I (t)$ 也可以是单调递减的,上面的凸峰状是另一种情况
SIS Model
Susceptible-Infective-Susceptible
即一个infected node在heal了后即刻转化为susceptible node
Epidemic Threshold
Epidemic Threshold $\tau = \frac{1}{\lambda_{1, A}}$,其中,$\lambda_{1, A}$ 是adjacent matrix $A$的最大eigenvalue。$A$ 是graph的邻接矩阵
有一个性质,$d_{ave} \le \lambda_{1, A} \le d_{max}$。这里 $d_{ave}$ 是图 $G$ 的average degree,$d_{max}$ 是max degree
Virus Strength $s = \frac{\beta}{\delta}$
Epidemic threshold是一个衡量当前virus能否导致epidemic的标准。对于一个virus,
- 如果 $s < \tau$,那么这个virus将会die out quickly
- 如果 $s \ge \tau$,那么这个virus将会导致epidemic
Influence
Independent Cascade Model
现在假设我们有一个directed graph $G$,edge $(v, w)$之间的边权 $p_{vw}$ 代表着 $v$ 如果被activated,他有 $p_{vw}$ 的概率向 $w$ 传递。这就是independent cascade model
Influence Set
在独立级联模型中,一个节点的影响力集合(influence set)是指激活该节点后,通过信息传播网络可以激活的所有节点的集合。
具体来说,当一个节点被激活时,它会尝试将信息传递给它的邻居节点。如果邻居节点的阈值大于等于当前传递信息的节点的随机数,则该邻居节点也会被激活,并且传递信息给它的邻居节点。这个过程会一直持续,直到没有新的节点被激活为止。
因此,如果我们知道一个节点的阈值和邻居节点的信息,我们就可以计算出激活该节点后,可以通过信息传播网络传递到的所有节点。这个集合就是该节点的影响力集合。
在实际应用中,我们可以使用影响力集合来评估节点的影响力大小,以及预测信息在社交网络中的传播规模和传播速度。
我们称一个node $u$的influence set为 $X_u$
$S$ is initial active set. $f(S):$ The expected size of final active set
一个initial active set $S$ 的 $f(S)$ 越大,他的影响力越大
现在有一个问题,我们要怎么找到一个大小为 $k$ 的initial set $S$,使得他的cascade size $f (S)$最大呢?
事实上,我们没法直接算出来,但是可以approximate
Hill Climbing
- Start with $𝑆_0 =\{\}$
- For $𝑖 = 1 … 𝑘$
- Take node $u$ that max $f (S_{i - 1} \cup \{u\})$
- Let $S_i = S_{i - 1} \cup \{u\}$
最红hill climbing得到的solution $S$会满足 $f (S) \ge (1 - \frac1e) \times \text{optimal answer}$
他会满足这个条件是因为,
$f$ 是单调的 (monotone),即我新增一个节点不会让他变小
$f$ is submodular,即我加入一个新node获得的收益越来越少
Mathematically,$\forall S \subseteq T$,$f (S \cup \{u\}) - f (S) \ge f (T \cup \{u\}) - f (T)$
我们也可以管他叫做diminishing returns
How to measure $f (S)$?
但是可以发现我们现在还有个最basic的问题没有解决,那就是怎么计算 $f (S)$
Repeating the diffusion process often enough (10000 times in the experiment)
Signed Network
Signed network实际上就是用边权符号的正负来表示两个person的是友好还是敌对关系,正数越大表示越友好,负数越小表示越敌对,整个signed network里面最basic的component叫做signed triangle
首先我们考虑undirected graph,那么里面的basic component就是undirected signed triangle,有几个最基本的intuition:
- Friend of my friend is my friend
- Enemy of enemy is my friend
- Enemy of friend is my enemy
我们称满足这三条定律的triangle是balanced的,反之则是unbalanced
可以发现实际上这当中的排列组合非常少,所以我们可以表达的更直白一些并且扩展到整张graph
Graph is balanced if every connected triple of nodes has:
- All 3 edges labeled +, or
- Exactly 1 edge labeled +
但实际上这个定律还能再次简化,最终变为
If all triangles are balanced, then either:
- The network contains only positive edges, or
- Nodes can be split into 2 sets where negative edges only point between the sets
Predicting Edge Signs
实际上,若一个graph不是complete的,我们还可以predict未知边的positive or negative
我们要做的实际上就是fill in edges从而使得我们的graph变成balanced的,这可以从local view和global view来看
- Local view: Fill in the missing edges to achieve balance
- Global view: Divide the graph into two coalitions
这两种view最后得到的结果是一样的
Concretely,
Local view:
- After filling in all missing edges, we have a signed complete graph
- Apply the balance theorem
- Obtains a division of the network into two sets that satisfies the second definition
Global view:
- Fill in positive edges inside X and inside Y, and fill in negative edges between X an Y
- Easy to see that all triangles will be balanced
对于local view来说,那么我们又如何快速判断一个graph是否balanced呢?
Graph is balanced if and only if it contains no cycle with an odd number of negative edges
对于global view来说,
缩点,使得每个supernode (就是缩出来的大点)中不存在negative edges
得到缩点后的图后,使用点叉法,寻找是否存在一个supernode是点也是叉
若存在,则说明unbalanced
之后我们需要怎么才能将这些node分为X和Y两个set呢?
使用BFS跑一边分层:
If there is no edge connecting two nodes in the same layer 即若不存在上图AB这样的edge
- Produce the desired division into X and Y by putting alternate layers in different sets
If there is an edge (negative edge) connecting two nodes in the same layer 即若存在上图AB这样的edge
Take two paths of the same length leading to the two ends of the end
Together with the edge itself forms an odd cycle
即这种情况必定会存在odd cycle
Signed Graph中的embeddedness
- Positive ties tend to be more embedded
- Positive ties tend to be more clumped together
All-positive network
- The subgraph consisting only of the positive links
All-negative network
- The subgraph consisting only of the negative links
Randomized baseline
- First randomly shuffle the edge signs in the full network
- and then extract the all-positive and all-negative networks
现在给出一个定义
Clustering: fraction of A-B-C paths in which the A-C edge is also present (thus forming a “closed” triad)
即看看有多少个closed triangle
他们之间的clustering大小是 all-positive > baseline > all-negative
Recommender
Formal Model
$C = $ set of costomers
$S$ = set of items
Utility function $u: C \times S \rightarrow R$,前面这个公式表示他是一个 $C \times S$,然后value表示 $R$ 的矩阵。其中 $R = $ set of ratings,即比如0~5星的评价
但我们可以发现这个model有一个key problem,就是这个utility matrix $U$ 是sparse的,即很多人没有rate most items
基于这个matrix我们可以给出三种推荐方式:
- Content-based
- Collaborative
- Hybrid
Content-based Recommender
基于内容的推荐系统通过分析项目的特征和用户的偏好,将相似的项目归为同一类别,然后向用户推荐与其之前喜欢的项目类似的项目(即类似且在utility matrix中highly rated的项目)。这种方法需要对项目的特征进行精细的分析和处理,以便准确地描述项目的属性和特征。
为了实现分类目的,我们首先需要给每个item create an item profile
Profile is a set of features
- movies: author, title, actor, director,…
- text: set of “important” words in document
那么我们要怎么样才能提取出important words呢?
Usual heuristic is TF.IDF (Term Frequency times Inverse Doc Frequency)
TF.IDF
TF-IDF的思想是:如果某个词语在一篇文档中出现频率高,并且在其他文档中出现频率低,则认为这个词语具有很好的区分能力,是该文档的关键词。
TF-IDF的计算分为两步:首先计算词语的TF值(Term Frequency),然后计算词语的IDF值(Inverse Document Frequency)。
词语的TF值表示该词语在文档中出现的频率,可以用以下公式计算:
$f_{ij} = $ 某个item $t_i$ 在document $d_j$ 中出现的次数
$$
TF_{ij} = \frac{f_{ij}}{\max_k f_{kj}}
$$
词语的IDF值表示该词语在文档集合中的区分能力,可以用以下公式计算:
$n_i = $ mention item $i$ 的doc个数
$N = $ total number of docs
$$
IDF_i = \log \frac{N}{n_i}
$$
最后计算TF.IDF score
$$
w_{ij} = TF_{ij} \times IDF_i
$$
那么此时text的profile,即那些important words就是TF.IDF score最高的那些words,同时我们还要记录他们的score
User Prediction Heuristic
这时我们可以根据上面的数据来进行预测,叫做predictioin heuristic
对于一个user profile $c$ & item profile $s$,estimate $u (c, s) = \cos (c, s) = \frac{c \times s}{|c||s|}$
Collaborative Filtering Recommender
基于用户的协同过滤推荐系统通过分析用户之间的相似性,来推荐与其相似用户喜欢的项目。具体来说,该方法首先计算用户之间的相似度,然后基于相似度来为目标用户推荐与其相似用户喜欢的项目(即不是根据current user的feature来进行推荐)。该方法的主要优点是易于理解和实现,但其缺点是存在冷启动问题(对于新用户没有足够的历史数据来计算相似度)和可扩展性问题(随着用户数量增加,计算相似度的复杂度会呈指数增长)。
Collaborative Filtering的recommend过程分为两个步骤:
- 计算用户之间的相似度 (similarity with active user)
- 预测目标用户对某个物品的评分
或者更detail一些:
- Select a subset of the users (neighbors) to serve as predictors
- Normalize ratings并根据所选邻居评级的加权组合计算预测
- 将具有最高predicted rating的项目作为推荐
Similarity Weighting
我们使用Pearson correlation coefficient between ratings for active $a$ & another user $u$ 来进行计算
$$
c_{a, u} = \frac{\text{cov} (r_a, r_u)}{\sigma_{r_a}\sigma_{r_u}}
$$
其中 $r_a, r_u$ 表示rating vectors,$\text{cov} (x, y)$ 是计算 $x, y$ 的协方差 (covarience)
评分向量通常是一个m维向量,其中m是物品的数量,每个元素表示用户对某个物品的评分值,评分值通常是一个实数,表示用户对该物品的喜好程度或重要程度。
我们还需要 Significance Weighting 来优化一下
Significance Weighting是协同过滤推荐算法中常用的一种加权方法,用于提高相似度计算的准确性和鲁棒性。他主要解决以下的scenario:有些用户或物品只评分了很少的物品,这些用户或物品的评分向量通常非常稀疏,导致相似度计算不准确或不可靠。
为解决这个问题,可以采用Significance Weighting方法,将那些评分较少的用户或物品的相似度计算结果进行加权处理。具体来说,可以使用以下公式计算两个用户 $u$ 和 $v$ 之间的相似度,其中,$s_{a, u}$ 是significance weights
$$
w_{a, u} = s_{a, u}c_{a, u} \
s_{a, u} =
\left\{
\begin{aligned}
&1 ~ \text{if} ~ m > 50 \
&\frac{m}{50} ~ \text{if} ~ m \le 50
\end{aligned}
\right.
$$
Neighbor Selection
之后就是neighbor selection,这一步就是对于一个active user $a$,将 $w_{a, u}$ 排序,找到the most similar $n$ users。或者也可以设定一个threshold,大于这个threshold都算similar
Rating Prediction
假设我们现在已经选定了 $n$ 个neighbor,那么就可以通过下面的公式来predict user $a$ 对item $i$ 的rating $p_{a, i}$ 了,
$$
p_{a, i} = \bar{r}a + \frac{\sum\limits{u = 1}^n w_{a, u} (r_{u, i} - \bar{r}u)}{\sum\limits{u = 1}^n w_{a, u}}
$$
其中 $u \in \{1, 2, …, n\}$
Matrix Factorization
但是上述方法还是有一些弊端,我们需要用Matrix Factorization来解决。那么为什么我们需要Matrix Factorization呢?
我们需要矩阵分解(Matrix Factorization)的原因有以下几点:
处理稀疏矩阵:在推荐系统中,用户-物品评分矩阵通常是非常稀疏的,即大多数用户和物品之间没有评分记录。传统的基于相似度计算的协同过滤算法在稀疏矩阵上表现不佳,因为相似度计算会受到缺失值的影响。矩阵分解可以将稀疏矩阵分解为两个低维度的矩阵,从而捕捉用户和物品之间的潜在关系和特征,避免了稀疏矩阵的问题。
解决冷启动问题:在推荐系统中,新用户和新物品通常没有评分记录,即存在冷启动问题。传统的基于相似度计算的协同过滤算法无法准确地为新用户和新物品进行推荐。矩阵分解可以利用潜在因子的特征表示新用户和新物品,从而在没有评分记录的情况下进行推荐。
提高推荐效果:矩阵分解可以捕捉用户和物品之间的潜在关系和特征,提高推荐效果。相比传统的基于相似度计算的协同过滤算法,矩阵分解能够更好地挖掘用户和物品的隐含特征,从而提高推荐的准确性和个性化程度。
支持增量学习:在实际应用中,评分数据通常是动态变化的,需要支持增量学习。矩阵分解可以通过优化算法实现增量学习,即在新数据到来时,只需更新部分参数,而不需要重新训练整个模型。
实际上本质上就是Matrix Factorization里能表达出的潜在因子起了主要作用